Java의 정석 기초편
Chapter11 컬렉션 프레임웍
1. 컬렉션 프레임웍
컬렌션 프레임웍이란? 데이터 군을 저장하는 클래스들을 표준화한 설계. 데이터 군을 다루고 표현하기 위한 단일화된 구조. (컬렉션: 다수의 데이터, 데이터 그룹. 프레임웍: 표준화된 프로그래밍 방식)
3가지 타입의 컬렉션데이터 그룹- List, Set, Map
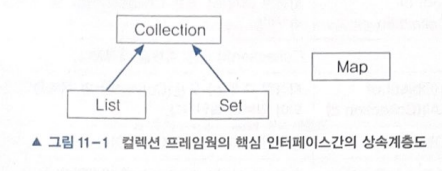

2. List인터페이스

ArrayList
기존의 Vector를 개선한 것.(Vector는 기존 작성된 소스와의 호환성을 위해 남겨둠.)
Object 배열을 이용해서 데이터를 순차적으로 저장. 배열에 더 이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성해 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장. 모든 종류의 객체를 담을 수 있음.
요소를 삭제하는 경우 삭제할 객체를 덮어쓰는 방식으로 처리. 배열에 객체를 순차적으로 추가 또는 마지막부터 삭제하면 데이터를 옮기지 않아도 되어 작업시간 ↓, 배열의 중간에 위치한 객체를 추가 또는 삭제할 경우 다른 데이터의 위치를 이동시켜야 하기 때문에 작업시간 ↑.
LinkedList
배열의 단점을 보완하기 위해서 고안. 배열은 모든 데이터가 연속적으로 존재하지만, 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성. 링크드 리스트의 각 요소들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성. 참조만 변경해주면 되기 때문에 추가와 삭제가 빠름. 불연속으로 위치한 요소들이 연결된 것이라 처음부터 n번째 데이터까지 차례대로 따라가야 접근 가능하므로 접근시간 ↑.
| 컬렉션 | 읽기(접근시간) | 추가/삭제 | 비고 |
| ArrayList | 빠름 | 느림 | 순차적인 추가삭제는 더 빠름. 비효율적인 메모리 사용. 데이터 개수가 변하지 않는 경우 사용. |
| LinkedList | 느림 | 빠름 | 데이터가 많을 수록 접근성 떨어짐. 데이터 개수 변경이 잦을 경우 사용. |
Stack과 Queue

순차적으로 데이터를 추가하고 삭제하는 스택에는 ArrayList와 같은 배열기반의 컬렉션 클래스가 적합하고, 큐는 데이터의 추가/삭제가 쉬운 LinkedList로 구현.
3. Set인터페이스

HashSet
중복된 값은 저장되지 않고, 저장 순서를 유지하지 않음. 저장순서를 유지하고자 한다면 LinkedHashSet 사용.
TreeSet
이진 검색 트리(레드-블랙트리)라는 자료구조의 형태로 데이터를 저장하는 컬랙션 클래스. 여러 개의 노드가 서료 연결된 구조로, 각 노드에 최대 2개의 노드를 연결할 수 있으며, 루트인 하나의 노드에서부터 시작해서 계속해서 확장.
정렬, 검색, 범위검색 성능↑, 노드의 추가, 삭제는 시간 ↑.
위아래로 연결된 노드는 '부모-자식관계'. 왼쪽에는 부모노드의 값보다 작은 값의 자식노드를, 오른쪽에는 부모노드의 값보다 큰 값의 자식노드를 저장.

class TreeNode {
TreeNode left; // 왼쪽 자식노드
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식노드
}
4. Map인터페이스
Hashtable은 이전의 것이므로 HashMap 사용 권장.
HashMap
키와 값을 묶어서 하나의 데이터로 저장. 키와 값은 (Object, Object)형태로 저장. 키는 유일, 값은 중복 허용.
많은 양의 데이터를 검색하는 성능↑

'공부일기 > JAVA' 카테고리의 다른 글
| JAVA 공부일기2-1 (0) | 2023.05.10 |
|---|---|
| JAVA 공부일기1-13 (0) | 2023.05.07 |
| JAVA 공부일기1-11 (0) | 2023.04.29 |
| JAVA 공부일기1-10 (0) | 2023.04.26 |
| JAVA 공부일기1-9 (0) | 2023.04.25 |




댓글